概述
Java虚拟机简称为JVM,JVM从整体上看,主要解决了以下几个问题:
- Java Class 二进制字节流的加载(ClassLoader)
- Java 程序的内存管理(GC & 运行时数据区)
- Java 程序的执行(执行引擎)
根据《Java虚拟机规范(Java SE 7版)》JVM的整体架构图如下:
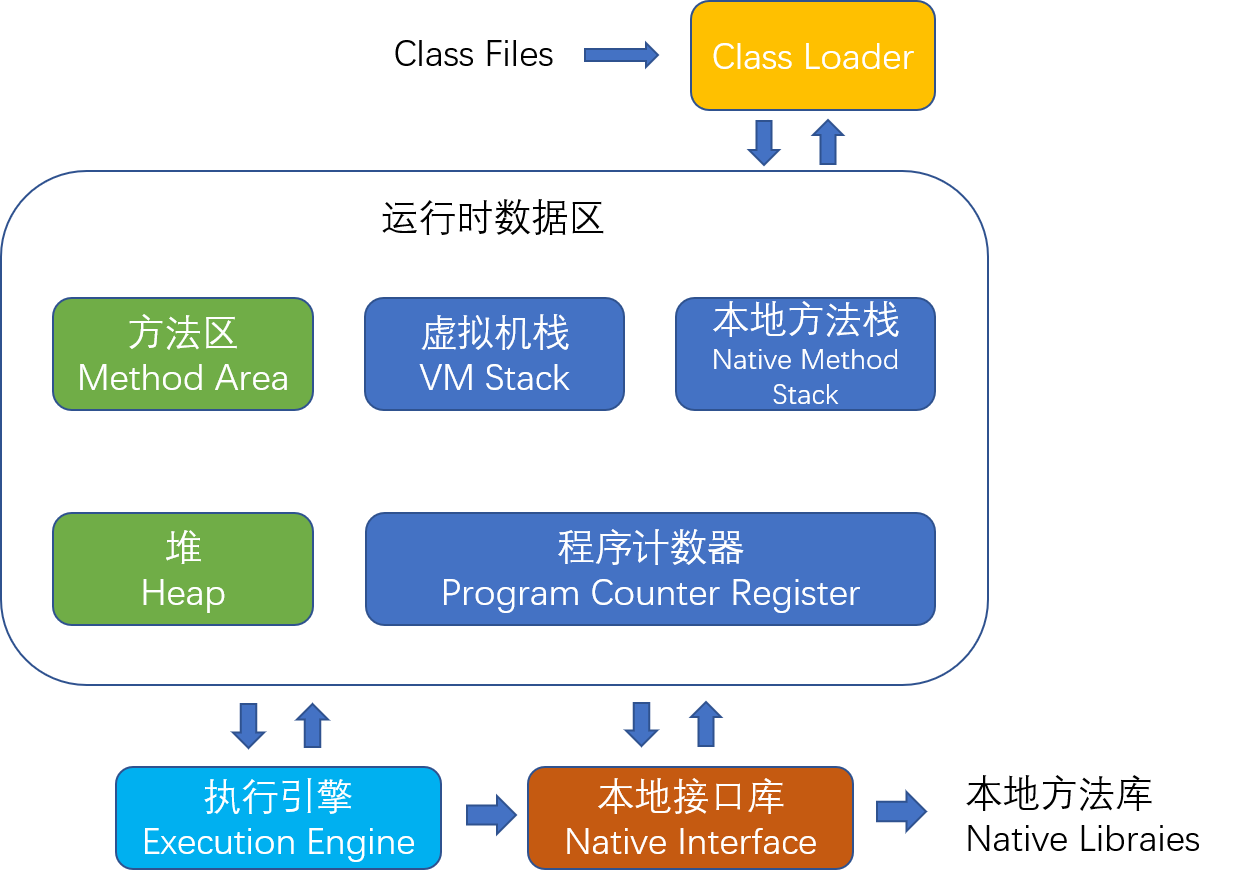
JVM主要由四部分组成:
- Class Loader:依据特定格式,加载class文件到内存
- Runtime Data Area: JVM内存空间模型,对于这部分的管理属于GC部分
- Execution Engine:对命令进行解析
- Native Interface:融合了不同开发语言的原生库为Java所用
类加载器
对于 Java 虚拟机来说,Class 文件是一个重要的接口,无论使用何种语言进行软件开发,只要能将源文件编译为正确的 Class 文件,那么这种语言就可以在 Java 虚拟机上运行。可以说,Class 文件就是虚拟机的基石。Class如图:
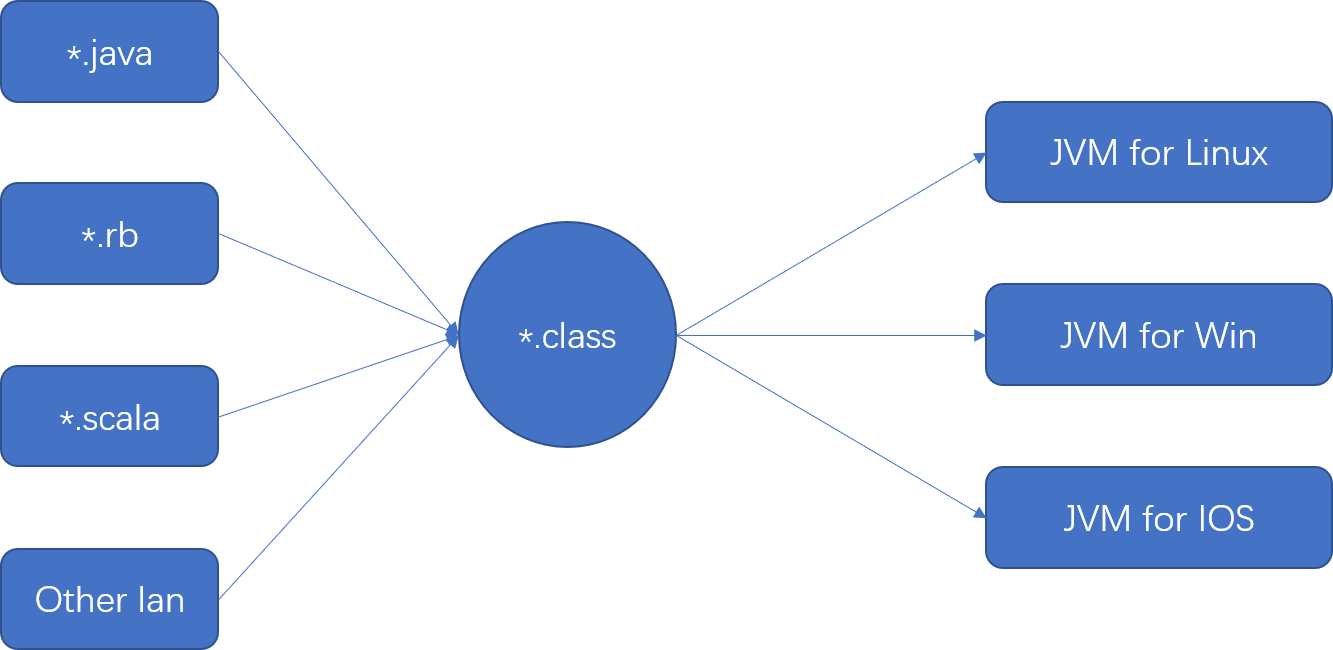
从上图可以看出,虚拟机不拘泥于 Java 语言,任何一个源文件只要能编译成 Class 文件的格式,就可以在JVM 上运行。Class 文件格式就像是一个接口,只要遵守这个接口,就能够在 JVM 上运行。同时,每个操作系统都有相对应的JVM。Java虚拟机通过类加载器将.class文件加载到虚拟机。
Java内存结构
运行时数据区
程序计数器
由于 Java 虚拟机的多线程时通过线程轮流切换并分配CPU时间片的方式来实现的,在任何一个确定的时刻,一个处理器都智慧执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间计数器互不影响,独立存储,我们称这类内存区域为 “线程私有的内存”。程序计数器主要有如下功能和特性:
- 当前线程所执行的字节码行号指示器(逻辑)
- 改变计数器的值来选取下一条需要执行的字节码指令
- 和线程是一对一的关系即“线程私有”
- 对Java计数,如果是Native方法则计数器值为Undefined
- 不会发生内存泄漏(OOM)
虚拟机栈
线程私有,生命周期和线程一致。描述的是 Java 方法执行的内存模型:每个方法在执行时都会床创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行结束,就对应着一个栈帧从虚拟机栈中入栈到出栈的过程。栈帧的结构如图:
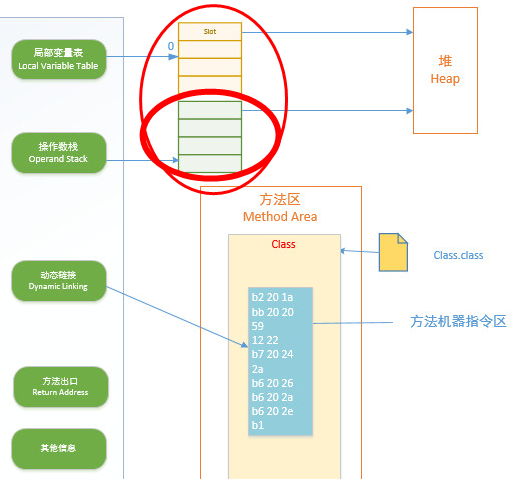
局部变量表:存放了编译期可知的各种基本类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型)和 returnAddress 类型(指向了一条字节码指令的地址)
操作数栈:jvm指令是基于操作栈的,也就是说,运算过程是在操作栈中进行的
动态链接:Class字节码的常量持中存有大量的符号引用,在运行期才将符号引用变成直接引用(也就是指向数据),可以是方法或者字段的引用
方法出口:即本方法执行后下一步指令的地址,方法正常退出时,调用者PC计数器的值就可以作为返回地址,异常退出时,返回地址是要通过异常处理器来确定
下图,add(1,2)栈帧的变化过程:
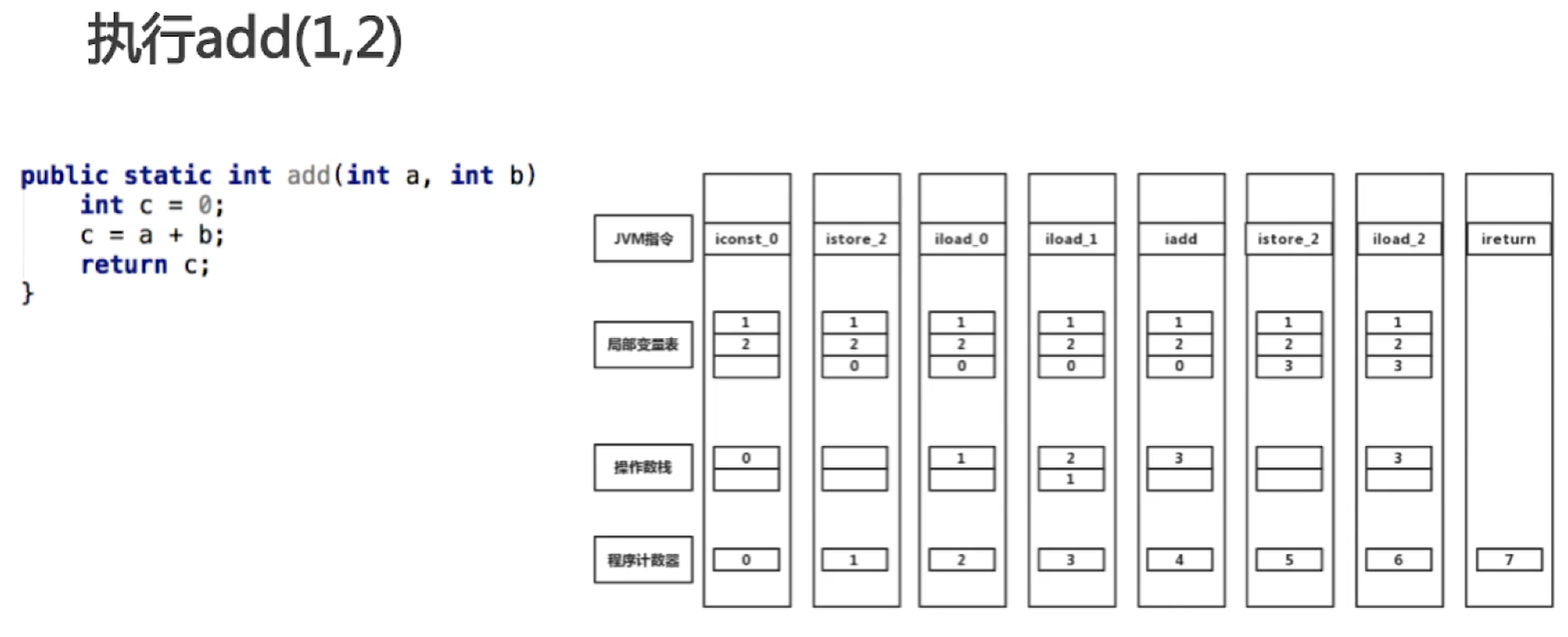
执行add方法反编译code如下:
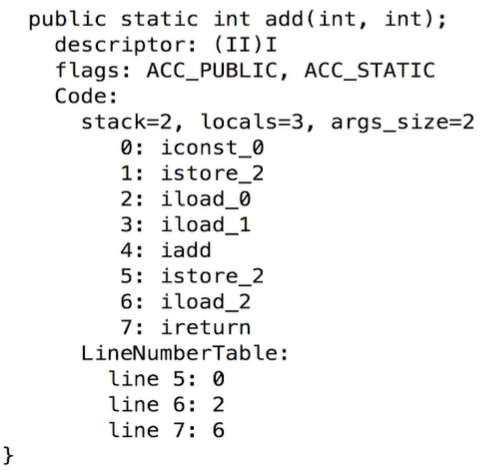
执行该方法时会创建一个栈帧,其中栈的深度(stack)为2,局部变量表容量(locals)为3,参数数量(args_size)为2,执行add方法分为7个jvm指令,8个命令执行过程分栈帧变化 :
- iconst_0:将0压入操作数栈中
- istore_2:将操作数栈顶元素pop出来,存入到局部变量index为2的位置
- iload_0:将局部变量index为0的数压入到操作数栈
- iload_1:将局部变量index为1的数压入到操作数栈
- iadd:将操作数栈中2和1都弹出来,并相加再压入栈顶
- istore_2:将操作数栈顶元素pop出来,存入到局部变量index为2的位置
- iload_2:将局部变量index为2的数压入到操作数栈
- 将操作数栈的栈顶元素返回出去
线程请求的栈深度(栈帧数)大于虚拟机栈所允许的深度,会报StackOverflowError。当虚拟机栈可以动态扩展时,而扩展时无法申请到足够的内存,会报OutOfMemoryError。
本地方法栈
区别于 Java 虚拟机栈的是,Java 虚拟机栈为虚拟机执行 Java 方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。而虚拟机规范中对本地方法栈中方法使用的语言,使用方式与数据结构并没有强制规定,因此具体的虚拟机可以自由实现它。甚至有的虚拟机(HotSpot虚拟机)直接就把本地方法栈和虚拟机栈合二为一。也会有 StackOverflowError 和 OutOfMemoryError 异常。
堆
对于绝大多数应用来说,这块区域是 JVM 所管理的内存中最大的一块。线程共享,主要是存放对象实例和数组。
Java堆可以位于物理上不连续的空间,但是逻辑上要连续。在实现时,既可以实现成固定大小的,也可以是可扩展的,不过当前主流的虚拟机都是按照可扩展来实现的(通过 -Xmx设置堆的最大值和 -Xms设置堆的初始值控制,一般Xmx和Xms设置成一样的,因为堆扩容时会导致内存抖动,影响程序运行时的稳定性)。如果在堆中没有内存完成实例分配,并且堆也无法扩展时,将会抛出 OOM 异常。
堆和栈的主要区别:
- 管理方式:栈自动释放,堆需要GC
- 空间大小:栈比堆小
- 碎片相关:栈产生的碎片远小于堆
- 分配方式:栈支持静态和动态分配,而堆只支持动态分配
- 效率:栈的效率比堆高
垃圾回收
Java 堆是垃圾收集器管理的主要区域,因此很多时候也被称为 “GC 堆(Garbage Collected Heap)”,从内存回收的角度来看,由于现在收集器基本都采用分代收集算法,所有Java 堆中还可以细分成:新生代和老年代;再细致一点的有 Eden 空间,From Survivor 空间,To Survivor 空间等。内部会划分出多个线程私有的分配缓冲区(Thread Local Allocation Buffer, TLAB)。
Java 程序员之所以不需要显式的释放内存,一切也都归功于 GC,GC 解放了 Java 程序员的双手。GC 系统会在后台清除无用的实例对象,释放内存空间。GC的内容相对比较多,这里就不多赘述。
方法区
方法区(Method Area )与 Java 堆一样,时各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息,常量,静态变量,即时编译器编译后的代码等数据。虽然Java 虚拟机规范把方法区描述堆的一个逻辑部分,但是它却有一个别名叫做(Non-Heap 非堆),目的应该是与Java 堆区分开来。
永久代
对于习惯在 HotSpot 虚拟机上开发,部署程序的开发者来说,很多人都更愿意把方法区称为 “永久代(Permanent Generation)”,本质上两者并不等价,仅仅是因为 HotSpot 虚拟机的设计团队选择把GC 分代设计扩展至方法区,或者说使用永久代来实现方法区而已,这样 HotSpot 的垃圾收集器可以像管理Java 堆一样管理这部分内存,能够省去专门为方法区编写内存管理代码的工作。
对于其他虚拟机并不存在永久代这个概念。原则上,如何实现Java 虚拟机属于实现细节,不受虚拟机规范约束,但使用永久代来实现方法区,更容易遇到内存溢出(永久代有 -XX:MaxPermSize 的上限)。因此,对于 HotSpot 虚拟机,已经放弃了永久代并逐步改为 Native Memory 来实现方法区的规划了,在JDK1.7版本中,已经把原本放在永久代的字符串常量池移出(符号引用(Symbols)**移至native heap,字面量(interned strings)和静态变量(class statics)移至java heap**)。
Java 虚拟机规范对方法区的限制非常宽松,除了和 Java 堆一样不需要连续的内存和可以选择固定大小或者可扩展外,还可以选择不实现垃圾回收。相对而言,垃圾收集行为在这个区域是比较少见的,但并非数据进入了方法区就如同永久代的名字一样“永久”存在了。这区域的内存回收目标主要是针对常量池的回收和对类型的卸载,一般来说,这个区域的回收“成绩”比较难以令人满意,尤其是类型的卸载,条件相当苛刻,但是这部分的区域的回收确实是由必要的。Sun 有几个Bug 就是应为HotSpot 虚拟机对此区域未完全回收导致内存泄漏。当方法区无法满足内存分配需求时,也将抛出OOM异常。
元空间
JDK 1.8开始,抛弃了永久代,使用元空间(Metaspace)作为方法区的实现。元空间和永久代最大的区别就是,元空间使用本地内存,而永久代使用JVM内存。元空间相比于永久代的优势:
- 字符串常量池存在于永久代中,容易出现性能问题和内存溢出
- 类和方法的信息大小难以确定,给永久代的大小指定带来困难,太小容易导致永久代溢出,太大容易导致老年代溢出
- 永久代会为GC带来不必要的复杂性
- 方便HotSpot与其他JVM如Jrockit集成
元空间内存管理:
- 在metaspace中,类和其元数据的生命周期与其对应的类加载器相同,只要类的类加载器是存活的,在Metaspace中的类元数据也是存活的,不能被回收
- 每个加载器有单独的存储空间
- 省掉了GC扫描及压缩的时间
- 当GC发现某个类加载器不再存活了,会把对应的空间整个回收
元空间使用一个块分配器(chunking allocator)**来管理Metaspace空间的内存分配。块的大小依赖于类加载器的类型。元空间中有一个全局的可使用的块列表(a global free list of chunks)**。当类加载器需要一个块的时候,类加载器从全局块列表中取出一个块,添加到它自己维护的块列表中。当类加载器死亡,它的块将会被释放,归还给全局的块列表。
运行时常量池
运行时常量区,属于方法区的一部分。用于存放编译期生成的各种字面量和符号引用。编译器和运行期(String 的 intern() )都可以将常量放入池中。内存有限,无法申请时抛出OOM。在JDK1.7版本中,已经把原本放在永久代的字符串常量池移出放入到堆中。因此,在1.7之前版本和之后的版本String的intern()方法返回有些不同:
- JDK1.6:当调用intern()方法时,如果字符串常量池先前已经创建了这个字符串对象,则返回池中该字符串的引用。否则将该字符串对象加入到字符串常量池中,并返回该字符串对象的引用
- JDK1.7+:当调用intern()方法时,如果字符串常量池先前已经创建了这个字符串对象,则返回池中该字符串的引用。否则,再判断该字符串对象是否已经存在Java堆中,存在则将堆中此对象的引用加入到字符串常量池,并返回该引用。如果堆中不存在,将该字符串对象加入到字符串常量池中,并返回该字符串对象的引用。
1 | String s1 = new String("a"); |
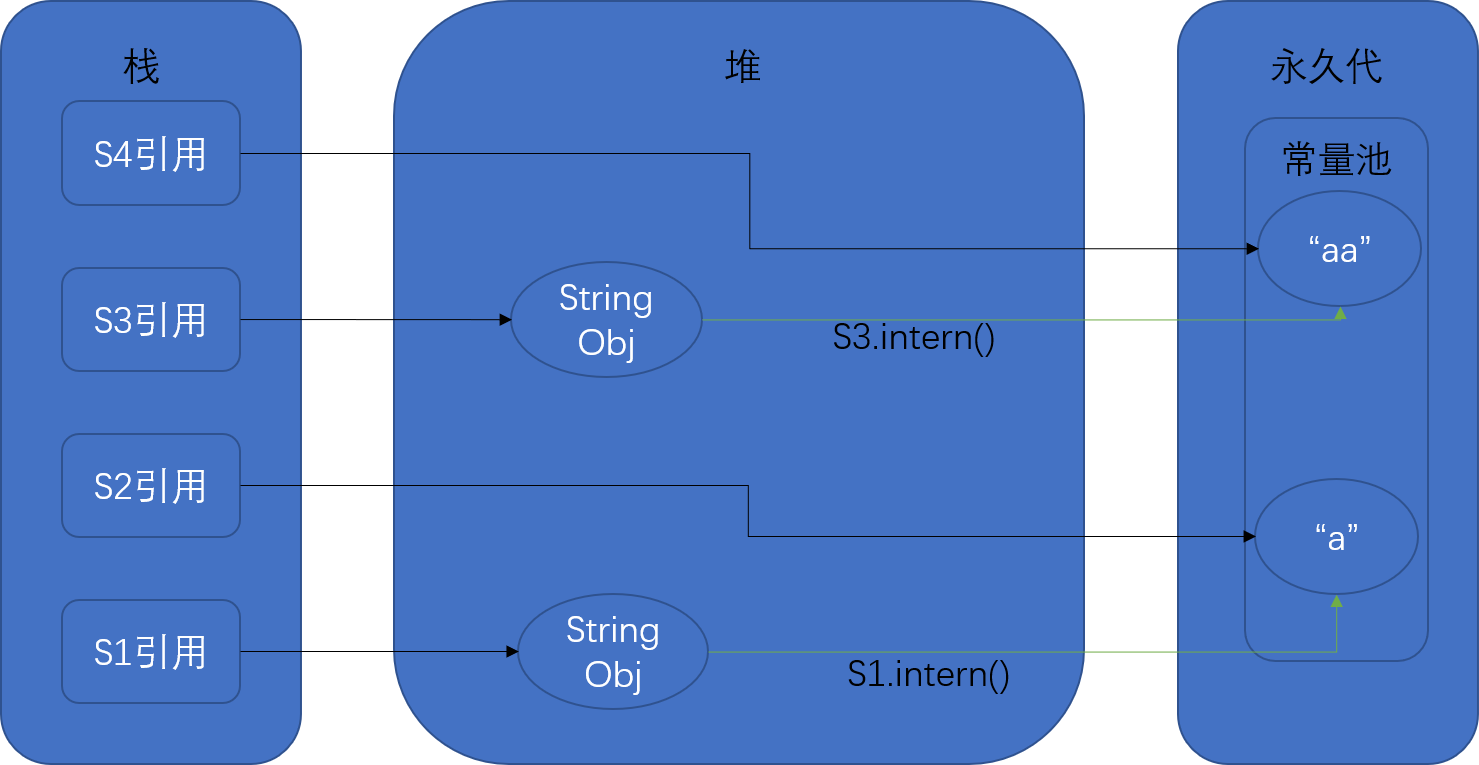
JDK1.6中,两个返回为false,因为s1和s3都是堆中对象的引用,s2和s4是常量池中对象的引用,则拿堆中对象地址和常量池对象地址想比较肯定不相等。
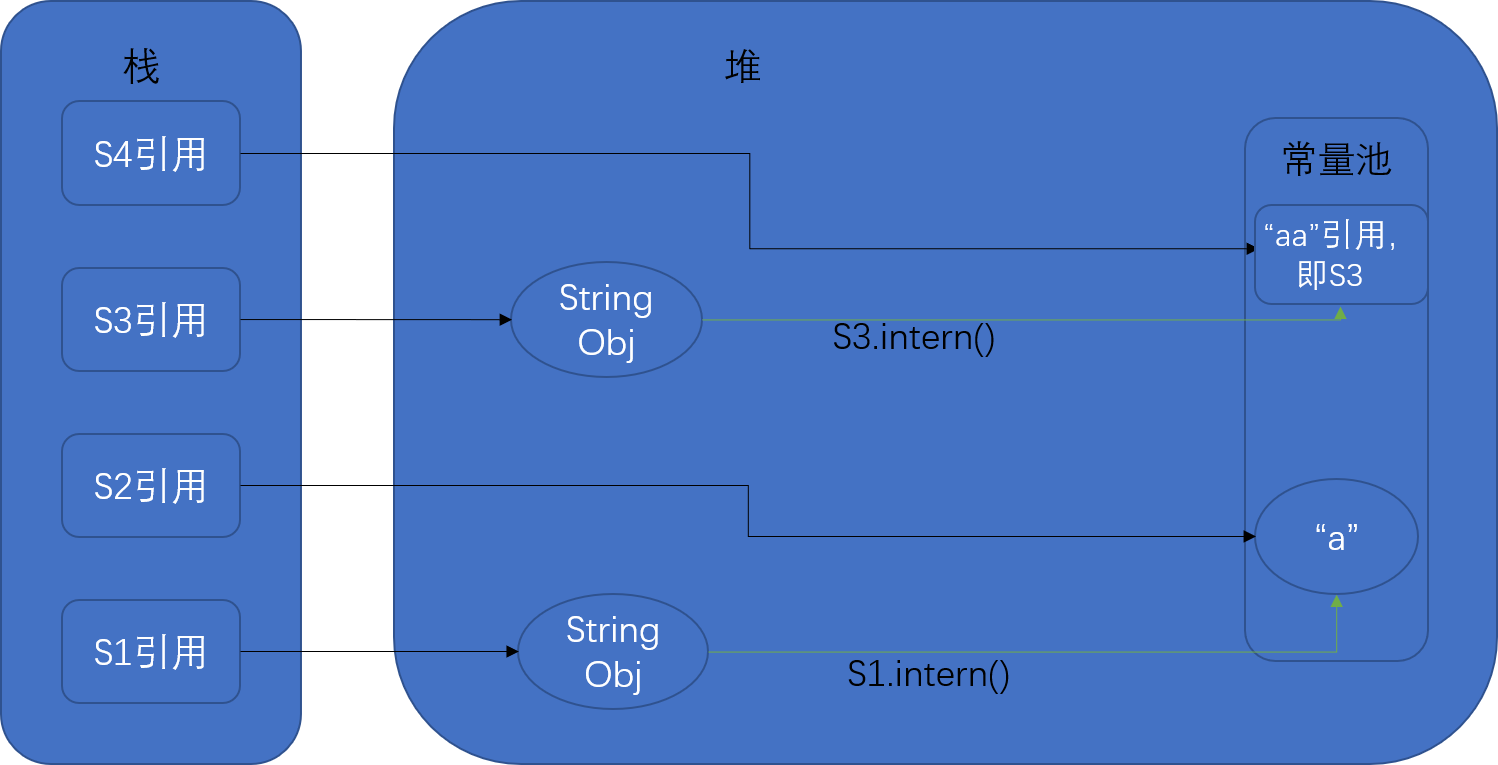
JDK1.7+中,第一个返回false,s1是堆中对象的引用,s2因为常量池中已有,所以s1执行intern方法之后,因为常量池中已存在“a”,所以s2=“a”时,s2是常量池对象引用,所以不相等。第二个返回true,因为s3执行intern方法之后,因为常量池中不存在“aa”,则将堆中的引用放到常量池中,s4=“aa”时,实际指向了堆中的字符串对象,所以相等。即JDK1.7中的字符串常量池可以放堆中的引用,可以减少一定的内存开销。
直接内存
直接内存(Direct Memory) 并不是JVM 运行时数据区的一部分,也不是 JVM 规范中定义的内存区域,但是这部分内存也被频繁的使用,而且也可能导致 OOM。
在 JDK 1.4 中新加入了 NIO 类,引用了一种基于通道(Channel)与缓冲区(Buffer)的 I/O 方式,它可以使用 native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场合中显著提高性能,因为避免了在 Java 堆和 Native 堆中来回复制数据。
显然,本机直接内存的分配不会受到 Java 堆大小的限制,但是,既然是内存,肯定还是会受到本机总内存(包括 RAM以及 SWAP 区或者分页文件)大小以及处理器寻址空间的限制。服务器管理员在配置虚拟机总参数时,会根据实际内存设置-Xmx 等参数信息,但经常忽略直接内存,使得各个内存区域总和大于物理内存限制(包括物理的和操作系统级别的限制),从而导致动态扩展时出现 OOM 异常。
执行引擎
执行引擎是Java虚拟机最核心的组成部件之一。虚拟机的执行引擎由自己实现,所以可以自行定制指令集与执行引擎的结构体系,并且能够执行那些不被硬件直接支持的指令集格式。所有的Java虚拟机的执行引擎都是一致的:输入的是字节码文件,处理过程是字节码解析的等效过程,输出的是执行结果。基于栈的字节码解释执行引擎的执行过程如上add方法。